Что такое дешифровка, или Окончание поиска
Что такое дешифровка, или Окончание поиска
Итак, мы подошли к последнему этапу длинного и тяжелого пути. Позади остались многие годы кропотливого и сложного труда, пролетевшие быстро, почти незаметно. Взбираясь на крутую вершину познания тайны письма жрецов майя, молодой дешифровщик, подобно скалолазу, преодолевал многочисленные препятствия. И вот остался последний и самый крутой подъем. Он требует полной отдачи сил, опыта и знаний, накопленных годами. Любая, даже малейшая ошибка отбросит исследование назад, и тогда найдутся ли силы, чтобы вновь попытаться достичь столь желанной вершины поиска?!
Триста знаков! Много это или мало? Как, по какому принципу собираются они вместе, заполняя страницы рукописей или каменные барельефы стел?..
В большинстве языков мира, в том числе и в языках семьи майя-кичэ, склонение и спряжение связаны с появлением в начале и конце слога грамматических показателей. В русском языке такими грамматическими показателями являются, например, хорошо знакомые нам окончания падежей, не имеющие сами по себе смысла и относящиеся к какому-нибудь осмысленному (знаменательному) слову. К грамматическим показателям относятся также различные частицы, предлоги, союзы. Именно они, словно сцепщики железнодорожного состава, скрепляют вместе разрозненные отдельные слова, связывая их в осмысленное предложение. При увязке слов друг с другом очень важную роль играет также их порядок в предложении, свойственный данному языку.
Приведем наипростейший пример. Возьмем пять слов: комната, стол, стоять, красный, зеленый. Заложена ли какая-нибудь идея (смысл) в этом наборе слов? По-видимому, нет. Однако, «включив» грамматические показатели русского языка, мы получим осмысленное предложение: «В красной комнате стоит зеленый стол».
В тексте, написанном известным или неизвестным письмом, корню слова (если это слово повторяется) Должна соответствовать устойчивая группа знаков. Грамматическим же показателем в начале или конце слова должны соответствовать меняющиеся и заменяющие друг друга знаки (Кнорозов называет их «переменными») перед или после устойчивой группы знаков.
Вновь обратимся за примером к русскому языку: в русском тексте сочетание трех букв (знаков) «дом» будет устойчивым, а падежные окончания — «дом-а», «дом-у», «дом-ом» — будут передаваться «переменными» буквами (знаками) «а», «у», «ом».
Языку майя, как уже говорилось выше, не чужды обе грамматические категории, и Кнорозов счел необходимым прежде всего выявить в иероглифических текстах майя устойчивые группы знаков (передающие корни слов древнего языка) и связанные с ними переменные знаки (передающие грамматические показатели). Следовало предположить, что их общее количество не должно быть велико, и их можно будет сопоставить с грамматическими показателями в текстах майя колониального периода («книги Чилам Балам»), записанных латиницей.
Работа по выявлению переменных знаков шла мучительно медленно и была чрезвычайно громоздкой. Ведь каждое сочетание знаков (иероглиф) приходилось прослеживать по всем рукописям и надписям майя. При этом постоянно возникали затруднения.
Мало того, что в иероглифических рукописях часто встречаются стертые и полустертые места, оборванные страницы и другой «производственный» брак, причиненный временем и не всегда умелым хранением этих текстов. Выяснились и иные враги дешифровщика: некоторые разделы рукописей, особенно Мадридской, были написаны на редкость небрежным почерком и к тому же со множеством ошибок (куда смотрели старшие жрецы?!). Не лучше обстояло дело и с каменными книгами — стелами: тропические ливни сильно размыли поверхность камней с надписями. На опознание многих знаков, различные проверки и перепроверки приходилось тратить слишком много времени и сил.
В результате проделанной работы Кнорозов свел иероглифы в группы. В каждую входили иероглифы, имеющие одинаковые устойчивые знаки и различные переменные, то есть различные грамматические показатели. Теперь можно было свести вместе слова с одинаковыми грамматическими показателями. По сравнению со сделанным такая работа была относительно несложной.
Сплошная регистрация всех случаев появления в тексте каждого иероглифа позволила одновременно выявлять и статистические данные о них. Самый простой способ применения статистики для целей дешифровки состоит в том, что подсчитывается, сколько раз каждый знак встречается в исследуемом неизвестном тексте; это абсолютная частота. Заручившись такими данными неизвестных нам знаков, следует подобным же образом обсчитывать тексты майя, записанные латиницей, то есть известными нам знаками — буквами. Зачем? Чтобы сопоставить неизвестные знаки с буквами (или группой букв), имеющими ту же частоту в известных текстах.
Однако в ряде разделов рукописей майя настойчиво повторяются отдельные иероглифы, очень редко встречающиеся в других местах. При сплошном подсчете легко может оказаться, что знак имеет большую частоту за счет многократного повторения одного и того же иероглифа, то есть за счет частого повторения какого-нибудь слова в некоторых разделах текста. В этом случае абсолютная частота знака (ровно как и иероглифа, в состав которого он входит) будет отражать не особенности языка, а особенности данного специфического текста с часто повторяющимся отдельным словом или словами (например, в тексте, рекламирующем, скажем, пылесос, слова «пылесос» и «пыль» будут повторяться значительно большее число раз, чем в любом другом). Чтобы избежать подобной ошибки, можно при подсчете частоты пропускать повторения одного и того же иероглифа (слова), получая относительную частоту, не зависящую от особенностей текста.
Однако установления абсолютной и относительной частоты знаков было еще недостаточно. Поэтому Кнорозов считал ближайшей задачей изучение переменных знаков, передающих грамматические показатели. Нужно было выявить частоту переменных знаков, а это означало, что при подсчете частоты нужно учитывать только те случаи, когда знак передает грамматический показатель, то есть стоит перед или после корня слова.
Вновь прибегнем к примеру из русского языка. Для того чтобы установить частоту показателя дательного падежа — «у» (в словах «дом-у», «храм-у», «пруд-у» и т. д.), нужно подсчитать, сколько раз буква «у» встречается в конце определенных слов, но при этом отнюдь не следует учитывать случаи, когда она входит в состав корня (как в слове «пруд»)!
Изучение частоты знаков, занимающих определенное место (позицию) в словах, получило название «позиционной статистики». Точный язык цифр — математический анализ снова пришел на помощь молодому советскому исследователю. С помощью позиционной статистики можно было сравнительно легко сопоставить грамматические показатели языка иероглифических текстов майя с грамматическими показателями языка майя колониального периода, сохранившегося в «книгах Чилам Балам».
Но Кнорозов не спешил начать сопоставление грамматических показателей древнего и нового языков майя, хотя выявление переменных знаков и их позиционной частоты давало такую возможность. Он решил еще более основательно подготовиться к преодолению последних и самых трудных шагов, все еще отделявших его от заветной цели. Поэтому он подвергает исследованию порядок слов в предложениях майя, используя свой метод позиционной статистики. Но теперь он применяет его уже не к отдельным знакам, а к целым иероглифам.
Выяснилось, что на втором и третьем местах в предложениях всех типов, как правило, стоят иероглифы, не имеющие в своем составе переменных знаков. Были все основания считать, что иероглифы этой группы передают подлежащее. В самом деле, именно подлежащее, то есть обычно имя существительное в именительном падеже, имеет меньше всего грамматических показателей.
Другая группа иероглифов отличалась, наоборот, наибольшим количеством переменных знаков. Иероглифы этой группы стояли, как правило, на первом месте в предложениях почти всех типов. Судя по большому числу переменных знаков, эти иероглифы должны были передавать глагольное сказуемое. По ходу дальнейших исследований оказалось, что иероглифы, передающие сказуемое, подразделяются на две группы, каждой из которых свойственны свои грамматические показатели. После иероглифов одной группы в предложениях стояло сразу подлежащее, тогда как после иероглифов другой почти всегда появлялись особые дополнительные иероглифы, а подлежащее отходило на третье место. Естественнее всего было отождествить первую группу с непереходными глаголами, а вторую — с переходными, требующими дополнения. Так оно и оказалось, ибо и в языке майя XVI века был аналогичный порядок слов в предложении. На первом месте обычно стояло глагольное сказуемое, а подлежащее занимало второе место или третье, если после сказуемого шло дополнение.
Только теперь Кнорозов располагал достаточно четкой классификацией иероглифов. О каждом из них можно было сказать, с какими грамматическими показателями он употребляется, какую часть речи передает и какую роль играет в предложении.
Казалось, можно переходить к последовательному сопоставлению грамматических показателей языка иероглифических текстов, то есть неизвестного языка и языка майя XVI века, известного нам. Известного? Однако оказалось, что грамматика «известного» языка изучена довольно слабо. И снова пришлось отложить решающий штурм и надолго засесть за изучение грамматики по текстам майя, записанным латиницей, и только после этого заняться подготовкой сравнительных материалов — выявлением набора грамматических показателей и их частоты в текстах XVI века.
Это была наиболее тяжелая и изматывающая работа. Она требовала абсолютной внимательности. Если возникали сомнения в правильности подсчета, нужно было начинать его с самого начала, и так по нескольку раз. Но самое обидное: не было никакой гарантии, что получаемые с таким трудом данные пригодятся для дальнейшей дешифровки. Так оно и было в ряде случаев, когда единственным результатом проделанной работы являлось выяснение того, что изучаемый грамматический показатель не имеет никаких аналогии в древнем языке. Неудивительно, что при первой же возможности в дальнейшем и Кнорозов, и другие исследователи стали перекладывать такого рода работу на «плечи» вычислительной техники.
Однако в целом расчеты Кнорозова на то, что сопоставление древних переменных знаков с известными грамматическими показателями (из языка XVI века) окажется сравнительно легким, вполне оправдались. В центр внимания исследователя попало несколько знаков, передающих употребительные грамматические показатели. Эти знаки оказались как бы в медленно, но верно сжимающемся кольце. Каждая новая дополнительная характеристика этих переменных знаков была подобна новому, появлявшемуся из засады щупальцу спрута. Они, эти щупальца-знаки, обвивались вокруг жертвы, неуклонно приближали свою привязку.
Среди переменных знаков особо выделялся знак
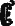 .
.
Он сочетался и с глаголами и с существительными и имел рекордную позиционную частоту. Такая же высокая частота в текстах XVI века была только у одного грамматического показателя — префиксо-местоимения «У» («он», «его»). Здесь не могло быть ошибки — знак определен точно, ему найден языковой эквивалент!
Сопоставление ряда других переменных знаков с известными грамматическими показателями также не составило особого труда. Наиболее часто встречающийся переменный знак
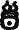 , передающий предлог, легко сопоставлялся по позиции и частоте с употребительным предлогом «ти» («в», «к»), а переменный знак
, передающий предлог, легко сопоставлялся по позиции и частоте с употребительным предлогом «ти» («в», «к»), а переменный знак
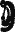 в конце переходных (требующих дополнения) глаголов явно соответствовал известному глагольному суффиксу прошедшего времени — «ах».
в конце переходных (требующих дополнения) глаголов явно соответствовал известному глагольному суффиксу прошедшего времени — «ах».
Но не все шло так гладко. Огромные затруднения встречались в тех случаях, когда произношение сильно изменилось. Например, употребительному суффиксу непереходных глаголов
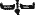 явно не было прямой аналогии в языке XVI века. Только значительно позже: в результате длительного изучения спряжения в языке майя Кнорозов сумел выяснить, что суффиксы непереходных глаголов XVI века («хи», «ни», «и») восходят к одному и тому же древнему суффиксу — «нхи». Иными словами, оказалось, что переменному знаку
явно не было прямой аналогии в языке XVI века. Только значительно позже: в результате длительного изучения спряжения в языке майя Кнорозов сумел выяснить, что суффиксы непереходных глаголов XVI века («хи», «ни», «и») восходят к одному и тому же древнему суффиксу — «нхи». Иными словами, оказалось, что переменному знаку
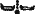 соответствует исчезнувший суффикс, от которого в языке XVI века сохранилось несколько «потомков» (с одинаковым значением).
соответствует исчезнувший суффикс, от которого в языке XVI века сохранилось несколько «потомков» (с одинаковым значением).
Так была решена ближайшая главная задача. Однако сопоставление грамматических показателей языка иероглифических текстов с известными грамматическими показателями языка майя XVI века еще не означало действительного чтения знаков. Отнюдь не исключено, что древние суффиксы или предлоги произносились иначе, чем в XVI веке. Чтобы установить их действительное чтение, нужно перейти к следующему этапу — чтению слов. Этот этап и был конечной целью — завершением дешифровки.
Но как, на основе каких данных можно попытаться прочесть сами слова? Существует ли такая возможность?
Кнорозов рассуждал следующим образом: если знак, передающий, например, предлог, который в XVI веке произносился как «ти», действительно имел такое чтение, тогда можно прочесть слова, в которых знак употребляется уже не как грамматический показатель, а для записи корневой части слова. Ведь знак должен читаться одинаково во всех случаях! Но чтобы считать чтение знака окончательно установленным, необходимо прочесть не меньше двух разных слов с этим знаком. Это и есть так называемые перекрестные чтения.
Установив, что знаки
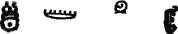
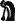 и т. д. передают грамматические показатели, которые в XVI веке соответственно произносились, как «ти», «ка», «ан», «у», «ах», Кнорозов, пользуясь заранее составленными сводками иероглифов, сумел подобрать нужные группы знаков. Так, слово
и т. д. передают грамматические показатели, которые в XVI веке соответственно произносились, как «ти», «ка», «ан», «у», «ах», Кнорозов, пользуясь заранее составленными сводками иероглифов, сумел подобрать нужные группы знаков. Так, слово
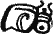 он прочел «му-ти», приписав первому знаку чтение «му»; второй же знак употреблялся для передачи предлога «ти». На языке XVI века слово «мут» означало «священное животное».
он прочел «му-ти», приписав первому знаку чтение «му»; второй же знак употреблялся для передачи предлога «ти». На языке XVI века слово «мут» означало «священное животное».
Это чтение подтвердилось в словах
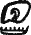 — «мука» («мук» — «раз») и
— «мука» («мук» — «раз») и
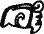 — «му-ан» («облачный», название месяца). Слово
— «му-ан» («облачный», название месяца). Слово
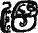 Кнорозов прочел «у-лу-му» («улум» — «домашний индюк»), приписав второму знаку чтение «лу», что подтвердилось в словах
Кнорозов прочел «у-лу-му» («улум» — «домашний индюк»), приписав второму знаку чтение «лу», что подтвердилось в словах
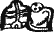 — «цу-лу» («цул» — «собака») и
— «цу-лу» («цул» — «собака») и
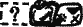 — «(бу) — лу-ку» («булук» — «одиннадцать»). В свою очередь, чтение знака
— «(бу) — лу-ку» («булук» — «одиннадцать»). В свою очередь, чтение знака
 — «цу» подтвердилось в слове
— «цу» подтвердилось в слове
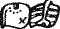 — «ку-цу» («куц» — «дикий индюк»); чтение знака
— «ку-цу» («куц» — «дикий индюк»); чтение знака
 — «ку» в слове
— «ку» в слове
 — «ку-чу» («куч» — «ноша») чтение знака
— «ку-чу» («куч» — «ноша») чтение знака
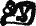 — «чу» — в слове
— «чу» — в слове
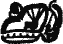 — «чу-ка-ах» («чуках» — «захватил») и т. д.
— «чу-ка-ах» («чуках» — «захватил») и т. д.
Цепляясь один за другой, знаки майя постепенно открывали дешифровщику свои сокровенные тайны, как раскрывает тайну кроссворда правильно найденное слово. Разумеется, чтение каждого нового неизвестного знака требовало перебора различных вариантов, пока не находился единственно правильный. Однако количество таких вариантов было уже сравнительно невелико, и с каждым новым расшифрованным и прочтенным словом их становилось все меньше и меньше.
Позиционная статистика — оригинальная система дешифровки неизвестных письмен, предложенная Кнорозовым, получила всеобщее признание и стала широко использоваться при дешифровке текстов древних народов, письмена которых считались навсегда утерянными. Именно она позволила включить в эту работу «думающие машины», решающие сложнейшие проблемы лингвистики на основе математического анализа.
Теперь непонятные, таинственные знаки неизвестных письмен не кажутся такими недоступными, непокорными. Благодаря титаническому труду Кнорозова мы твердо знаем, что каждый из них должен иметь свойственную только ему, вполне определенную частоту (повторяемость) и занимать определенное место в «блоке» — сочетании знаков. Иными словами, знаки имеют свой определенный «паспорт» с вполне точной «пропиской» (позицией в блоке) и частотой (повторяемостью). В иероглифической письменности в соответствии с этим «паспортом» и происходит разделение знаков на корневые, грамматические и фонетические, хотя и возможны случаи, когда один знак может являться владельцем целых двух «паспортов».
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Французская литература (окончание)
Французская литература (окончание) Дюма (1802–1870) Вопрос 2.1У Александра Дюма (отца) такое множество сочинений, что я не стану у Вас интересоваться: какие из них Вам известны.Сделаем так: я перечислю Вам некоторые сочинения, а Вы определите, какие из них принадлежат
Что такое хорошо, а что такое плохо?
Что такое хорошо, а что такое плохо? Возник у меня как-то с ребятами разговор о двух очень разных, ни в чем не похожих друг на друга сочинениях. Одно из них они слышали по радио, другое — в концертном зале. В исполнении первого принимали участие певцы-солисты, хор и большой
«ЧТО ТАКОЕ ХОРОШО И ЧТО ТАКОЕ ПЛОХО »
«ЧТО ТАКОЕ ХОРОШО И ЧТО ТАКОЕ ПЛОХО» Хороший человек, славный мальчик, приятный юноша, замечательная личность, герой, гений.:Так человека хвалят.А за что? И всюду ли за одно и то же?И всюду ли, всегда ли за одно и то же ругают?Конечно, нет. За примерами ходить недалеко. Каждый
Что такое дешифровка
Что такое дешифровка В строго научном понимании дешифровка означает отождествление знаков исследуемого письма (текста) со словами языка, записанного, как предполагается, при помощи этих знаков или их сочетаний, совокупность которых в разнообразных комбинациях и
Язык и дешифровка
Язык и дешифровка Продолжим разговор о дешифровке неизвестных письмен. Он был прерван на том самом месте, когда выяснилось, что молодому советскому ученому Юрию Кнорозову благодаря разработанной им оригинальной системе числовых показателей удалось доказать, что
Окончание банкета
Окончание банкета Об окончании обеда предупреждает подача кофе. Покидать торжество раньше времени позволительно исключительно по уважительной причине, объяснив причину хозяевам.Если гости не торопятся покидать праздник, негласным сообщением может стать убранная со
ЧТО ТАКОЕ ХОРОШО И ЧТО ТАКОЕ ПЛОХО
ЧТО ТАКОЕ ХОРОШО И ЧТО ТАКОЕ ПЛОХО НУЖНЫЕ, ХОТЯ И «ДРУГИЕ» О хорошей и плохой речи полезно знать многое. В этих заметках пока говорилось о правильности ее, чистоте, точности и богатстве. Но, по-видимому, существуют и другие ее качества? И может быть, эти «и другие» не менее
Глава IX ЦАРСТВО АИДА (окончание) ЗАГРОБНЫЕ НАКАЗАНИЯ
Глава IX ЦАРСТВО АИДА (окончание) ЗАГРОБНЫЕ НАКАЗАНИЯ Эпизод с Аяксом завершает тему «былых соратников»; кровь перестает использоваться в качестве предлога к общению, и теперь перед Одиссеем просто проплывают видения различных наказаний и прочих реалий загробного мира.
Эстетика Ренессанса (окончание)
Эстетика Ренессанса (окончание) В первых статьях об эстетике Ренессанса я коснулся ее философских основ, это прежде всего неоплатонизм и гуманизм, с переходом к эстетике отдельных художников, разумеется, лишь первейших гениев, у которых, несмотря на индивидуальные